Advancing AI with Mixture of Agents
Introduction
As Large Language Models (LLMs) continue to evolve and proliferate, they've become powerful tools across a wide range of applications. At Catena Labs, we've been exploring innovative solutions to enhance LLM integration and performance, leading to three key outcomes:
- The release of Crosshatch, a platform providing access to various "model mixes”, including the new coding mix discussed below
- A new coding mix that outperforms state-of-the-art models by 20% on the Bigcodebench (Instruct/Hard) benchmark by aggregating responses from the best models available
- The creation of moa-llm, an open-source Python package for mixture of agents experimentation (Github)
One of the primary hurdles in working with LLMs is determining which model is best suited for each specific task or domain. With new models being released at an unprecedented pace and performance benchmarks constantly shifting, staying current with the optimal options has become increasingly difficult.
This challenge is compounded by the fact that no single model excels at everything – a model that performs exceptionally well on text summarization might lag in code generation tasks.
As we've worked to address these issues, we've been driven by several key motivations:
- Explore multi-LLM orchestration approaches that go beyond simple routing, understanding what's possible when combining multiple models
- Investigate the potential of open-source models as viable alternatives to commercial options, aiming to make them more accessible
- Improve the performance of AI-assisted coding tools, with a particular focus on enhancing the capabilities of Cursor, a tool we use daily.
These goals led us to explore a technique called Mixture of Agents (MoA). This approach aims to harness the collective strengths of multiple LLMs, potentially offering solutions that outperform any single model. Our work with MoA has yielded some interesting results.
In the following sections, we'll examine the concept of Mixture of Agents in more detail, discussing our experiments, results, and the potential implications for the future of LLM integration.
We'll also introduce the moa-llm package and explore how these approaches might contribute to advancing AI-assisted development and other applications. Our goal is to share our findings and tools with the community, fostering further innovation and collaboration in this exciting field.
Understanding Mixture of Agents
Mixture of Agents is an interesting approach to leveraging multiple LLMs in a coordinated manner. At its core, MoA arranges LLMs in feed-forward Directed Acyclic Graph (DAG), creating a system that's greater than the sum of its parts. This architecture typically consists of two types of components: proposers, which are LLMs that generate initial responses to user input, and aggregators, which synthesize these outputs into a final, refined response.
The concept of MoA gained significant attention through the work of Together.ai. Their research demonstrated that MoA could achieve performance comparable to or even exceeding some of the most advanced individual models, including GPT-4 on certain benchmarks. One of their key observations was the "collaborativeness" of LLMs – the tendency of models to generate better responses when presented with outputs from other models, even if these other models are less capable on their own.
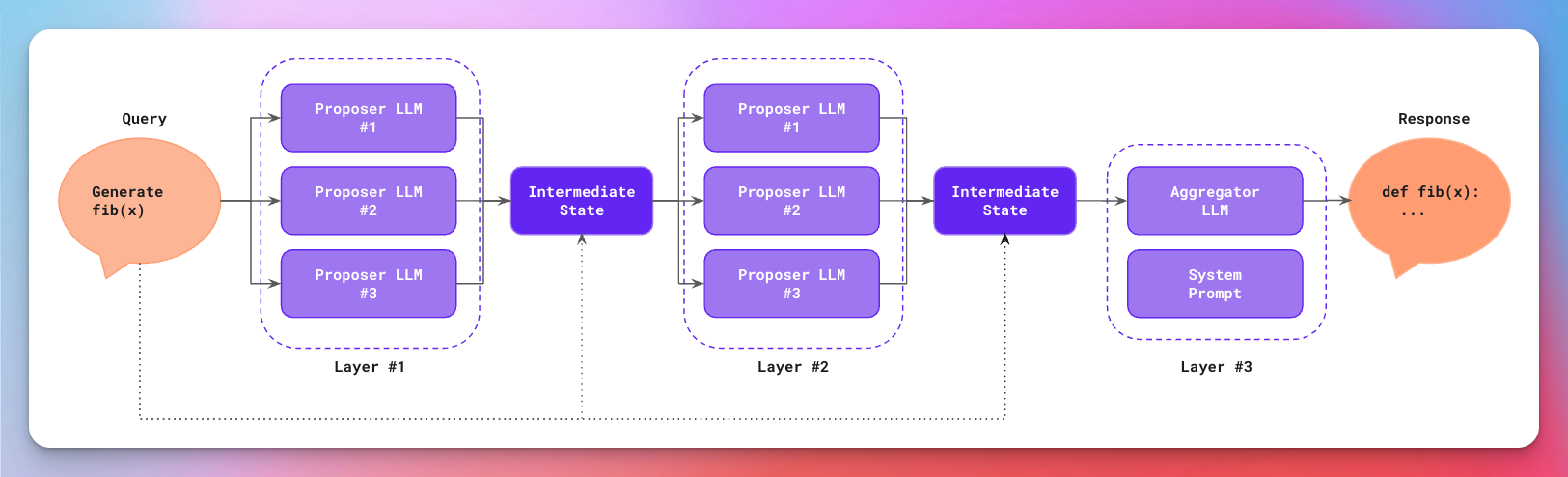
An example 2-layer mixture of agents set-up (original illustration by AI Makerspace)
Together.ai's experiments showed consistent improvements in model performance when leveraging responses from other models. For instance, they found that each model's score on AlpacaEval 2.0 increased significantly when provided with responses from other models, even when the reference response quality was lower than the model's own. This phenomenon underscores the potential of MoA to harness diverse perspectives and capabilities from various models.
The benefits of the MoA approach extend beyond just improved performance. By combining multiple models, MoA offers the potential for more robust and versatile AI systems. It allows for the integration of models with different strengths, potentially covering a wider range of knowledge domains and capabilities than any single model could provide. This diversity can lead to more nuanced and comprehensive responses, especially in complex tasks that require multifaceted understanding (creative writing, translation etc.)
Moreover, MoA presents opportunities for cost optimization in AI deployment. In some scenarios, using a combination of smaller, more specialized models might provide better results than relying on a single, more expensive large model. This approach could be particularly valuable in situations where using commercial models is not feasible due to budget constraints or data privacy concerns.
The flexibility of the MoA architecture also opens up possibilities for task-specific optimization. Different combinations of models can be employed for different types of queries, allowing for fine-tuned performance across various domains. This adaptability makes MoA a promising approach for creating more versatile AI systems that can handle a wide range of tasks effectively.
Recent research has further highlighted the potential of approaches similar to MoA. Studies on repeated sampling and the performance of smaller models under fixed compute budgets have shown that generating multiple outputs and selecting the best one can lead to significant improvements in task performance. These findings align with the core principles of MoA and suggest that there's still much to explore in terms of optimizing model combinations and selection strategies.

The repeated sampling procedure introduced by Brown, Juravsky, and Ehrlich in collaboration with Google DeepMind
As we continue to develop and refine MoA techniques, we're uncovering new ways to leverage the strengths of multiple AI models effectively. This approach represents a shift in AI research and development, moving beyond the pursuit of ever-larger individual models towards more sophisticated, collaborative systems. The promise of MoA lies not just in its potential to improve performance, but in its ability to create more adaptable, efficient, and capable AI systems that can better meet the diverse needs of real-world applications.
Building a Superior Coding Assistant with MoA
Our exploration of Mixture of Agents (MoA) led us to an exciting application: creating a high-performance coding assistant. This project aimed to leverage the strengths of multiple models to outperform state-of-the-art systems in code generation tasks. Here's how we approached this challenge and what we discovered along the way.
Methodology and Experiment Design
We focused our experiment on the BigCodeBench benchmark, specifically targeting its "hard" subset of coding tasks. BigCodeBench is designed to evaluate the true programming capabilities of large language models (LLMs) in a realistic setting, featuring complex instructions and diverse function calls. This benchmark aligns well with our goal of creating a coding assistant that can handle sophisticated programming challenges.
Our process involved several key steps. First, we established baselines by running the hard subset evaluation on top-performing models, including GPT-4o, Claude 3.5 Sonnet, and GPT-4. This gave us a clear picture of current state-of-the-art performance so we could begin an apples-to-apples comparison. Next, we generated MoA configurations using various permutations of these models, experimenting with different combinations as proposers and aggregators.
For each configuration, we followed a consistent evaluation process. We generated code by passing the instruct prompt to the MoA system, tested the code using the provided Docker container for reproducibility, and calculated the Pass@1 score. This score represents the system's ability to produce correct code on the first attempt, a crucial metric for real-world coding assistance.
Performance Improvements and Results
Our experiments yielded promising results, demonstrating the potential of MoA in the coding domain. Here's a summary of our findings:
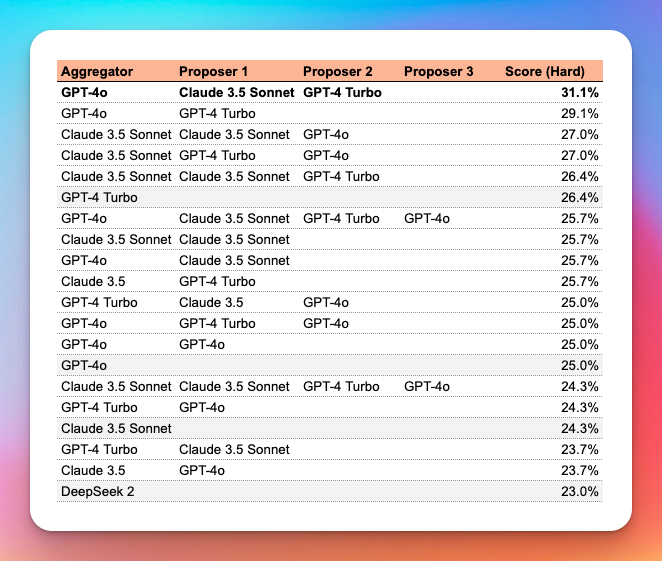
Our results: the top mix has 31.1% Pass@1 score compared to the best single model (GPT-4 Turbo)
Our optimal MoA configuration, which used Claude 3.5 Sonnet and GPT-4 Turbo as proposers with GPT-4o as the aggregator, achieved a Pass@1 score of 31.1% on the BigCodeBench hard subset. This represents a 20% improvement over GPT-4 Turbo's performance of 26.4%, which was our strongest baseline model.
These results are particularly encouraging given the challenging nature of the BigCodeBench hard subset. The tasks in this benchmark closely resemble real-world coding scenarios, making our performance gains relevant for practical applications.
Future Directions and Ongoing Research
While our initial results are promising, we recognize that this is just the beginning of our exploration into MoA for coding assistance. We're committed to expanding our research in several key areas:
- Broader Benchmark Evaluation: We plan to test our MoA approach on other benchmarks like SWE-Bench. Although SWE-Bench is more focused on agentic workflows, evaluating our system on diverse benchmarks will provide a more comprehensive understanding of its capabilities and limitations.
- New Models: New models (especially open source ones) are released almost daily and we want to continue investigating their performance as part of MoAs.
- Prompt Engineering: We want to explore how to chain layers together with different prompts focused on self-reflection, tree of thought, and other techniques. This library allows you to modulate how "connected" each layer is.
- Specialized Nodes: We're investigating the use of fine-tuned models with specialized prompts tuned for specific languages and frameworks (e.g., an MOA tuned for Java vs. Python).
- Latency and Cost Considerations: While our current mix shows great performance gains, we're actively working on optimizing latency and cost. Our goal is to create a system that not only outperforms individual models but does so in a computationally efficient manner.
- Expanded Task Coverage: Beyond coding tasks, we're exploring how our MoA approach can be applied to a broader range of software development activities, from requirements analysis to debugging and code review.
- Optimization Strategies: We're investigating ways to optimize our MoA configurations further. This includes exploring different routing strategies, such as pre-routing queries to specific models or mixes based on task complexity. We're also examining how factors like the number of proposers, aggregator configurations, and temperature settings affect performance.
Practical Applications and Availability
To make our advancements in MoA-based coding assistance accessible to developers, we've integrated our top-performing mix into Crosshatch, our new product offering. Crosshatch provides these sophisticated MoA configurations as a simple, OpenAI-compatible API, making it easy for developers to leverage advanced AI capabilities in their projects.
You can demo the mix here. We’ve been dogfooding it for a couple of weeks and love it. In fact, it was instrumental in building the moa-llm package itself.
As we continue to refine our approach and expand our research, we're excited about the potential of MoA to improve AI-assisted coding. Our work demonstrates that by thoughtfully combining the strengths of multiple models, we can create systems that surpass the capabilities of even the most advanced individual models. This opens up new possibilities for improving developer productivity and tackling increasingly complex programming challenges.
Introducing moa-llm: Open-Source MoA Orchestration
As our exploration of Mixture of Agents (MoA) progressed, we recognized the need for a flexible, robust tool to facilitate experimentation and implementation of MoA architectures. This led to the development of moa-llm, our open-source Python package designed to empower researchers and developers in the AI community to explore into the possibilities of MoA.
The Genesis of moa-llm
Inspired by the promising results from Together AI's work and our own experiments, we set out to create a framework that would allow for systematic exploration of MoA configurations. moa-llm is the result of this effort, providing an accessible platform for orchestrating multiple models in complex, multi-step processing pipelines.
Key Features and Capabilities
moa-llm offers a range of features designed to support flexible and powerful MoA implementations that resemble neural networks (how meta!):
- Flexible Multi-Layer Architecture: The package supports an arbitrary number of layers, including multiple proposal layers and aggregation layers. This flexibility allows users to create deep and complex query processing pipelines tailored to their specific needs.
- Customizable LLM "Neurons": Each LLM in the network can be configured with its own parameters, including system prompts and weights. This granular control enables fine-tuned influence of different models within the MoA structure.
- Diverse Aggregation Strategies: moa-llm provides various methods for synthesizing responses, including different system prompts, input concatenation techniques, and even random dropout for controlled variability in outputs.
- Asynchronous Processing: By utilizing asynchronous calls, moa-llm enables multiple LLMs to process information simultaneously, improving overall performance and efficiency.
- Broad Model Support: The package is compatible with a wide range of LLM providers and models, offering flexibility in choosing the most suitable models for specific tasks or experiments.
Empowering Experimentation and Innovation
One of the primary goals of moa-llm is to lower the barrier to entry for MoA experimentation. With this package, developers and researchers can:
- Create custom MoA architectures tailored to specific tasks or domains
- Experiment with different combinations of models and layer configurations
- Fine-tune system prompts and aggregation strategies for optimal performance
- Analyze the impact of various parameters on output quality and processing time
Looking to the Future
As we continue to develop moa-llm, we're excited about several potential areas of improvement:
- Advanced Aggregation Logic: Implementing sophisticated ranking systems to better combine outputs from different models.
- Meta-Learning Approaches: Exploring ways to "train" an MoA by adjusting weights or system prompts using an LLM as a judge.
- Novel Network Architectures: Investigating new ways to structure MoA networks for improved performance or specialized tasks.
- Optimization Techniques: Developing methods to balance performance gains with computational efficiency.
By open-sourcing moa-llm, we hope to accelerate research and development in the field of MoA, fostering a collaborative environment where ideas can be shared, tested, and refined. As we collectively explore what's possible with language models, we believe that approaches like MoA will play a crucial role in creating more capable, nuanced, and effective AI systems.
We're keen to see how the community will build upon and extend these ideas, and we look forward to the innovative applications and insights that will emerge from this collaborative effort.
Conclusion
Our exploration of Mixture of Agents (MoA) has yielded promising results, particularly in the realm of AI-assisted coding. Our MoA configuration achieved a 20% improvement over the current best model on the BigCodeBench hard subset, demonstrating the potential of this approach to yield material improvements in quality.
Key outcomes of our work include:
- A high-performing coding mix that outperforms state-of-the-art models
- The open-source moa-llm package for MoA experimentation
- Crosshatch, our new product offering these mixes as a simple, OpenAI-compatible API
These developments open new avenues for AI model integration and performance optimization. As we continue to refine our MoA approach, we're exploring applications beyond coding, including creative writing, roleplay, and complex translation.
We encourage the AI community to experiment with moa-llm and contribute to its development. The future of AI lies not just in individual model capabilities, but in how we can effectively combine and leverage multiple models for enhanced performance and versatility.
Get in touch with us on Discord
Get started with Crosshatch and learn more in our docs
Contribute on the moa-llm Github repo