Beyond Single Models: Exploring LLM Mixes
Keeping up with the latest and greatest LLMs can feel like a full-time job. New models are released almost weekly, each claiming to push the boundaries of what's possible. For developers, this rapid evolution presents both exciting opportunities and significant challenges. How do you choose the right model for your project? How can you ensure your application stays current without constant rewrites? And how do you balance cutting-edge performance with practical concerns like cost and latency?
This article introduces the concept of "mixes" as a potential solution to these challenges. We'll explore two types of mixes - Index Mixes and Synthesis Mixes - and discuss how they can simplify LLM integration while potentially enhancing application performance and flexibility.
The Challenge of Model Selection
Let's face it: choosing the right LLM for your project is tough. With new models constantly emerging and performance benchmarks shifting, it's easy to feel like you're always a step behind. What's top-of-the-line today might be old news tomorrow.
At the frontier of LLM development, it's often the data quality, training processes, and post-training optimization that set models apart. These nuances can be hard to discern from the outside, making it challenging for developers to make informed choices.
To complicate matters further, measuring model quality isn't straightforward. While standardized evaluations provide a basis for comparison, they often fall short in capturing the overall "vibe" or user experience of interacting with a model. Many developers resort to informal "vibe checks," directly interacting with models to get a feel for their capabilities. Initiatives like the LMSys Chatbot Arena Leaderboard attempt to provide more nuanced comparisons, but interpreting and applying these results to specific use cases remains complex.
Adding to the complexity is the fact that no single model excels at everything. A model that's great at creative writing might not be as good with code generation. For developers working on multi-faceted applications, this variability necessitates a deep understanding of each model's strengths and weaknesses.
It's clear that developers need a better way to navigate this complex landscape. This is where the concept of mixes comes in, offering a path to simplify model selection while maximizing performance.
Index Mixes: Always Using the Top-Performing Model
Imagine if you could always use the best-performing model without constantly monitoring leaderboards and updating your code. That's the promise of Index Mixes.
An Index Mix automatically routes user requests to the current top-performing model based on respected industry leaderboards. When you use an Index Mix, your API call is seamlessly directed to the model currently leading the pack, without any additional input from you.
This approach offers several key advantages:
- You always have access to top performance without the need for constant evaluation and manual selection.
- Your application is future-proofed, automatically benefiting from new, better-performing models as they emerge.
- Integration is simplified, requiring just a single API endpoint and key.
Index Mixes could cater to various needs:
- Language-specific mixes that always use the best model for a particular language (e.g., Chinese, French, Spanish).
- Task-specific mixes for specialized tasks like coding, leveraging benchmarks like LMSYS Chatbot Arena's category leaderboards, the Scale.ai SEAL Leaderboards, or Bigcodebench.
- Domain-specific mixes for areas like vision or image generation.
While Index Mixes offer significant benefits, they do come with challenges. The index needs regular updates to reflect the latest rankings, and some top-ranked models might not be immediately available through API gateways. However, for many developers, the advantages of always having access to top-tier performance without the hassle of constant model evaluation will outweigh these concerns.
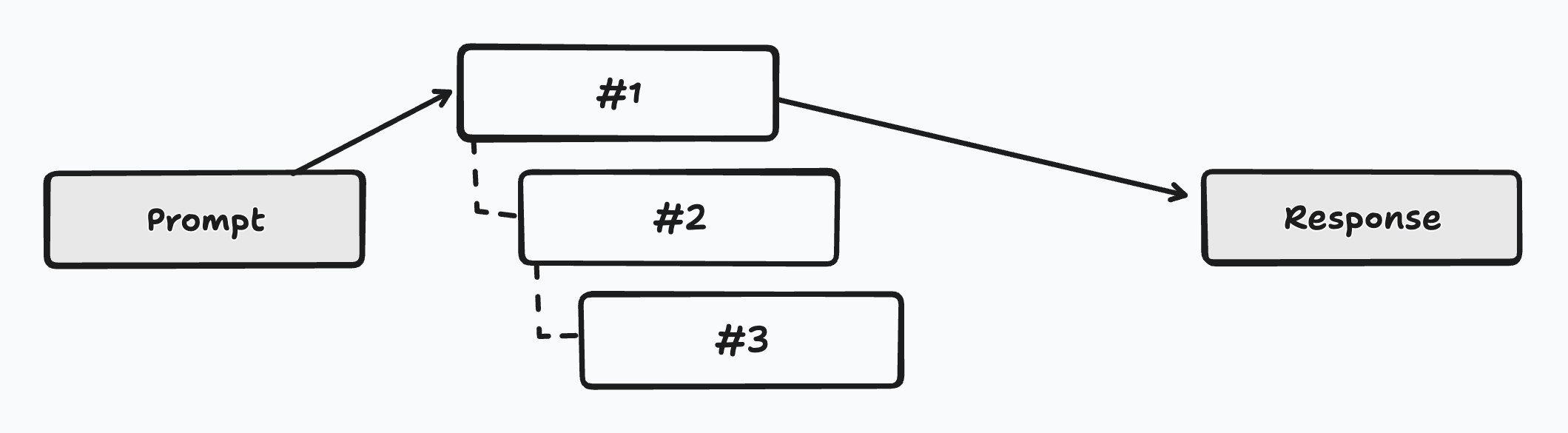
A simple mix indexed on a leaderboard. In this example, the mix will use the #1 ranked model first and fallback if necessary.
Synthesis Mixes: Harnessing the Power of Multiple Models
While Index Mixes focus on using the single best model, Synthesis Mixes take a different approach by leveraging the strengths of multiple models simultaneously. This method, inspired by the Mixture of Agents (MoA) concept pioneered by Together AI, aims to produce responses that are more comprehensive and nuanced than those generated by any single model.
A Synthesis Mix typically involves multiple stages:
- Several models (called "proposers") generate initial responses to a query.
- One or more "aggregator" models then synthesize these responses into a final, cohesive output.
This approach is based on the idea that different models have unique strengths and perspectives. By combining these diverse viewpoints, we can create a system that's greater than the sum of its parts.
Synthesis Mixes could be particularly valuable for tasks that benefit from diverse perspectives or where there isn't a single "correct" answer. Think about applications like:
- Summarization, where different models might focus on various aspects of a text.
- Translation, where combining outputs could capture nuances and idiomatic expressions more effectively.
- Creative writing, where a synthesis of ideas could lead to more innovative content.
- Complex problem-solving, leveraging multiple approaches to tackle intricate issues.
While Synthesis Mixes offer exciting possibilities, they also come with challenges. Orchestrating multiple models increases complexity and could lead to higher latency and costs compared to using a single model. Finding the right balance of models and effectively combining their outputs requires careful experimentation and tuning.
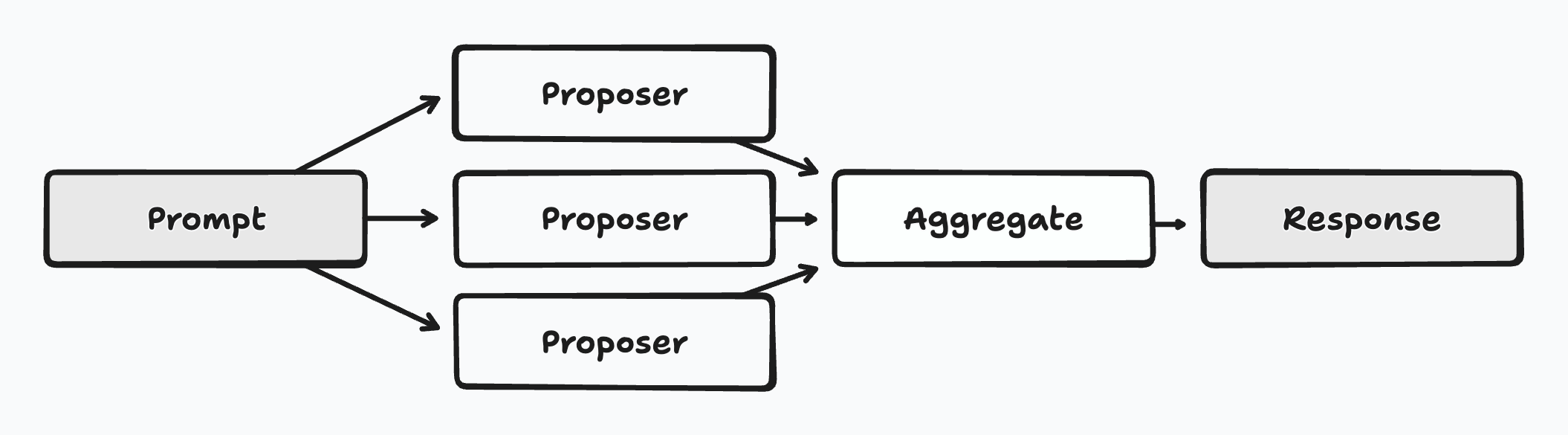
An example of a synthesis mix with three proposers (they could be different models, or the same model with different prompts, for example) and an aggregation model that synthesizes the final response.
Crosshatch: Simplifying LLM Integration
Both Index Mixes and Synthesis Mixes offer powerful ways to leverage LLMs, but implementing them from scratch would be a daunting task for most development teams. That's where Crosshatch comes in.
Crosshatch, Catena Labs' upcoming product, aims to make these advanced LLM integration techniques accessible to all developers. It's designed to address several key pain points:
- Model Selection: No more agonizing over which model to choose. Crosshatch's mix approach ensures you always have access to top-performing models.
- Integration Complexity: Crosshatch works as a drop-in replacement for existing LLM integrations. Just get an API key and replace the base_url in your code.
- Performance Optimization: Crosshatch's mixes are pre-optimized to deliver high-quality results across various tasks.
- Cost Management: With usage-based pricing, you only pay for what you use, making it easier to manage costs and scale efficiently.
By abstracting away the complexities of model selection and optimization, Crosshatch allows you to focus on what really matters - your core application logic. It future-proofs your applications, ensuring they benefit from the latest advancements in LLM technology without requiring constant updates.
Conclusion: The Future of LLM Integration
The rapid advancement of LLMs offers exciting possibilities for developers, but also presents significant integration and management challenges. Index Mixes and Synthesis Mixes represent two approaches to addressing these issues:
- Index Mixes aim to simplify model selection by automatically routing requests to top-performing models based on current benchmarks.
- Synthesis Mixes explore the potential of combining outputs from multiple models to achieve more robust or nuanced results.
While these approaches show promise, they also come with their own complexities and trade-offs that developers need to consider.
In our upcoming articles, we'll delve deeper into the practical aspects of implementing and using mixes:
- We'll introduce a Python package designed to facilitate the creation of custom Mixture of Agents workflows.
- We'll examine a coding-focused Synthesis Mix, comparing its performance against individual top-tier models.
- We'll provide step-by-step guides for integrating these mixes into existing AI-powered applications.
These articles will focus on concrete implementations, performance metrics, and code examples, aiming to provide developers with practical insights for leveraging these techniques in real-world projects. By exploring these topics in depth, we hope to contribute to the ongoing discussion about effective LLM integration and usage in software development.