Building a High-Performance Open-Source Coding Mix
We have found Mixture of Agents (MOA) to be a powerful approach to enhance the capabilities of language models., especially for coding generation. MOAs combine multiple AI models in a structured manner, typically involving "proposer" models that generate initial responses and "aggregator" models that synthesize and refine these proposals. This approach allows us to leverage the strengths of different models, potentially producing results that surpass the capabilities of any single model.
At Catena Labs, we've been exploring the potential of MOAs for coding tasks, with our previous work demonstrating that carefully crafted commercial MOAs can outperform even the most advanced individual models. However, the reliance on commercial models presents challenges in terms of cost, speed, and flexibility.
Driven by these considerations, we set out to create an MOA for coding that relies solely on open-source models. Our goal was to match or exceed the performance of commercial solutions while offering additional benefits. The results of this experiment have been remarkably promising:
- Cost-Effectiveness: Our new open-source mix is 56% cheaper than our previous MOA using only commercial models.
- Competitive Performance: It outperforms single models like GPT-4, Claude 3.5 Sonnet, and OpenAI's o1-preview on benchmark tasks, while only marginally underperforming compared to our best commercial MOA.
- Improved Speed: The mix demonstrates faster response times compared to commercial alternatives.
- Open-Source Foundation: By using only open-source models, we've created a solution that offers greater transparency, customizability, and reduced dependency on proprietary technologies.
The new open source coding mix will be available soon on Crosshatch. The commercial version is already available and we use it as our daily driver for coding at Catena Labs.
In this blog post, we'll take you through our journey of creating this open-source coding MOA. We'll discuss:
- Our methodology in selecting and combining open-source models
- The experimental process of finding the optimal configuration
- Performance results from rigorous benchmarking, including cost and speed comparison with commercial alternatives
This exploration into open-source AI models for coding assistance represents a significant step forward in making advanced AI tools more accessible, efficient, and flexible for developers. Whether you're a software engineer, an AI researcher, or a tech leader, our findings offer valuable insights into the future of AI-assisted development and the potential of open-source models in this rapidly evolving field.
The Challenge: Building a High-Performance Open-Source Coding Mix
Creating a Mixture of Agents (MOA) for coding using only open-source models while matching commercial solutions presented several significant challenges:
- Model Selection: Identifying open-source models capable of handling complex coding tasks at a level comparable to top commercial models.
- Performance Gap: Matching or exceeding the high benchmarks set by models like GPT-4, Claude 3.5 Sonnet, and the new o1-preview.
- Optimal Configuration: Determining the best combination of models for the MOA, requiring extensive experimentation with various permutations.
- Speed and Efficiency: Ensuring our open-source mix could compete not just in accuracy, but also in response time.
- Cost-Effectiveness: Balancing high performance with operational costs to create an economically viable solution.
- Benchmarking: Developing a robust evaluation process to meaningfully compare our mix against commercial alternatives.
Our goal was to create an open-source coding MOA that could serve as a compelling alternative to commercial solutions, offering comparable performance with added benefits of transparency and cost-effectiveness. The following sections detail our approach to overcoming these hurdles and the remarkable results we achieved.
Our Approach: Experimenting with Permissive Non-Commercial Models
To tackle the challenge of creating a high-performance open-source coding MOA, we adopted a systematic approach. Our methodology was designed to thoroughly explore the potential of combining different open-source models while maintaining a rigorous evaluation process.
Model Selection and Configuration Generation
We began by selecting three powerful open-source models known for their coding capabilities: Llama 3.1 405B, DeepSeek-2.5, and Mistral Large 2. These models were chosen not only for their strong individual performance but also for their potential to complement each other in an MOA setup.
To explore the space of possible combinations, we leveraged our moa-llm package. This tool, designed specifically for MOA experimentation, allowed us to generate unique MOA configurations for each permutation of the three models. With moa-llm, we could flexibly assign roles (proposer or aggregator) to each model within the MOA structure and easily adjust parameters and prompts for each model in the configuration.
The power of moa-llm lies in its ability to facilitate rapid experimentation. We could quickly generate and modify configurations, allowing us to explore a wide range of MOA structures. This flexibility was crucial in our quest to find the optimal combination of models for coding tasks.
Parallel Execution and Evaluation
To speed things up we turned to Modal, a cloud computing platform that enabled us to run all MOA configurations in parallel. This approach dramatically reduced our total execution time and allowed us to scale our computational resources dynamically based on the workload.
For each MOA configuration, we ran all 148 tasks from the BigCodeBench Instruct Hard dataset. This benchmark was chosen for its comprehensive coverage of complex coding scenarios, providing a robust test of each MOA's capabilities. Each MOA generated code responses for the given tasks, which were then processed and sanitized to ensure they were in a format suitable for evaluation.
The evaluation process itself was carried out using the Docker container provided by the BigCodeBench team. This container allowed us to execute the generated code in a sandboxed environment and run the provided unit tests against the code. We recorded pass/fail results for each task, calculating a Pass@1 score for each MOA configuration. This score represents the percentage of tasks correctly solved on the first attempt, providing a clear metric for comparing the performance of different configurations.
In the following section, we'll dive into the results of this extensive experimentation, revealing the top-performing open-source MOA configuration and analyzing its performance in comparison to commercial alternatives.
Results, Performance Analysis, and Cost Comparison
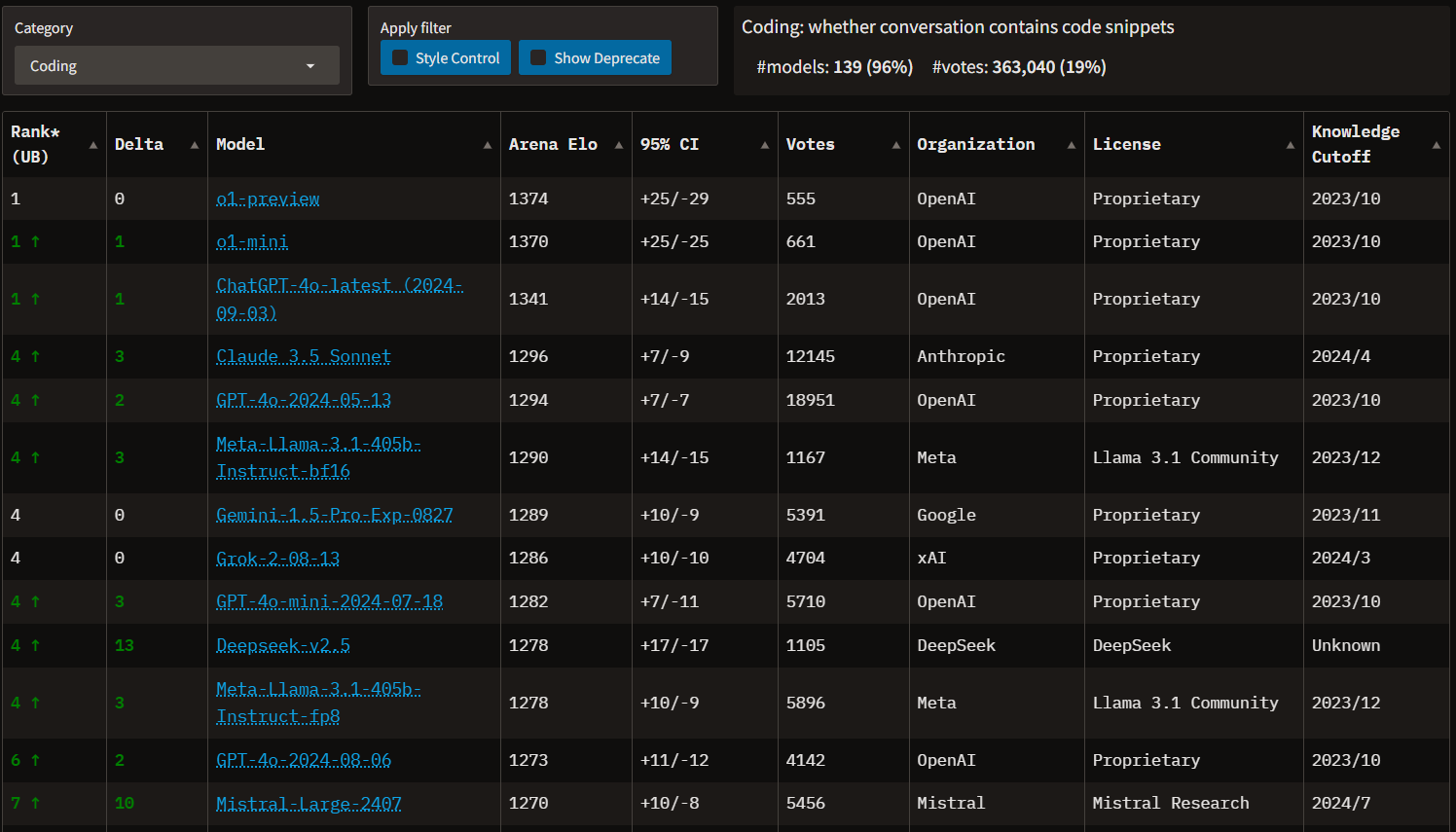
Our experiments with various MOA configurations yielded a clear winner among the open-source model combinations. The most effective configuration for our open-source coding MOA consists of DeepSeek-2.5 and Mistral Large 2 as proposers, with Llama 3.1 405B serving as the aggregator. This combination achieved an impressive 28.4% Pass@1 score on the Bigcodebench Instruct Hard dataset, a challenging benchmark for code generation tasks.
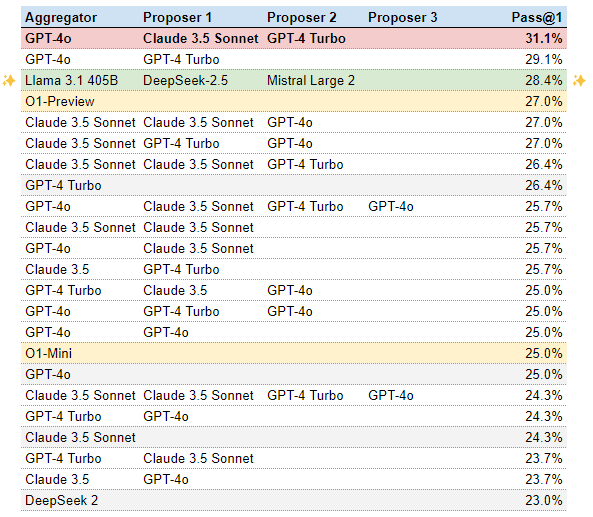
The success of this particular configuration can be attributed to several factors. DeepSeek-2.5 and Mistral Large 2 are both excellent at code generation, ranking #5 and #8 respectively on the LMSys coding leaderboard at the time of writing. Their diverse approaches to code generation likely provide a rich set of initial proposals for the aggregator to work with. Llama 3.1 405B, currently the top-performing open-source model on the LMSys coding leaderboard (ranked #5 overall), serves as an ideal aggregator. Its superior capabilities allow it to effectively synthesize and refine the proposals from the other two models. This configuration strikes a balance between leveraging the unique strengths of each model and ensuring that the final output benefits from their collective intelligence.
While our open-source MOA doesn't quite match the performance of our top commercial MOA (with a score of 31.1%) , it outperforms several leading individual commercial models. The new o1-preview and o1-mini scored 27% and 25% respectively, GPT-4 Turbo achieved a 26.4% Pass@1 score, and Claude 3.5 Sonnet reached 24.3%. This puts our open-source MOA in elite company, demonstrating that carefully crafted combinations of open-source models can compete with some of the most advanced commercial offerings.
One of the most significant advantages of our open-source MOA is its cost-effectiveness. Our analysis shows that this configuration is 56% cheaper than our commercial MOA.
- For the first proposer, DeepSeek-2.5 costs $0.14 per 1M input tokens and $0.28 per 1M output tokens, compared to Claude 3.5 Sonnet at $3 per 1M input tokens and $15 per 1M output tokens.
- The second proposer, Mistral Large 2, costs $2 per 1M input tokens and $6 per 1M output tokens, while GPT-4 Turbo in our commercial MOA costs $10 per 1M input tokens and $30 per 1M output tokens.
- The aggregator, Llama 3.1 405B on Together, costs $5 per 1M input tokens and $15 per 1M output tokens, which is the same price as GPT-4o used in our commercial MOA.
These price differences translate to substantial cost savings, especially at scale, making our open-source MOA an economically viable alternative for many applications. Our MOA is cheaper than o1-mini but performs 14% better.
In addition to its cost advantages, our open-source MOA also demonstrates superior speed compared to the commercial coding MOA. DeepSeek-2.5 and Mistral Large 2 are significantly faster in generating responses compared to GPT-4 Turbo, which, despite its high performance, can take 3-10 seconds per response. Together.ai's fast inference endpoint for the 405B model ensures that the aggregation step doesn't become a bottleneck. This speed advantage is crucial for real-world applications where response time is a critical factor, such as in interactive coding assistants or automated code review systems.
Our open-source MOA configuration presents a compelling alternative to commercial models, offering competitive performance, significant cost savings, and faster response times. It outperforms several leading commercial models in complex coding tasks while being 56% cheaper than equivalent commercial MOA setups and providing quicker code generation. These results demonstrate that carefully constructed open-source MOAs can not only compete with but in some aspects surpass commercial offerings, providing a powerful, cost-effective, and efficient solution for AI-assisted coding tasks.
The implications of these findings are significant for the field of AI-assisted coding. They suggest that organizations and developers can achieve high-quality results without necessarily relying on the most expensive commercial models. By leveraging open-source models in clever combinations, it's possible to create systems that are not only performant but also more accessible and cost-effective. This could democratize access to advanced AI-assisted coding tools, potentially accelerating innovation across the software development industry.
Conclusion and Future Directions
Our exploration into open-source Mixture of Agents (MOA) for coding tasks has yielded promising results, demonstrating that carefully constructed combinations of open-source models can achieve performance comparable to, and in some aspects surpassing, commercial alternatives. This approach not only offers significant cost savings and speed improvements but also opens up new possibilities for AI-assisted coding.
The success of our open-source MOA configuration underscores the potential of combining multiple models to leverage their collective strengths. By using DeepSeek-2.5 and Mistral Large 2 as proposers and Llama 3.1 405B as an aggregator, we've created a system that outperforms several leading commercial models while offering substantial cost savings and faster response times.
Looking ahead, we see several exciting directions for further research and development:
- Exploring New Open-Source Models: The landscape of open-source language models is rapidly evolving. We're particularly excited about incorporating new models like Qwen 2.5, which has shown promising results in coding tasks. As new open-source models emerge, we'll continue to evaluate their potential as both proposers and aggregators in our MOA configurations.
- Experimenting with Advanced Topologies: While our current setup uses two proposers and one aggregator, we're keen to explore more complex architectures. This could involve using more than two proposers or implementing multiple layers of aggregation. While these approaches may increase cost and latency, the potential quality improvements could be significant, especially for asynchronous workflows where real-time response isn't critical.
- Integrating Commercial Models: Despite our focus on open-source models, we recognize the value of commercial offerings. We plan to experiment with incorporating new commercial models into our MOA configurations. For instance, we're interested in exploring the potential of using OpenAI's o1-preview as an aggregator and o1-mini as a proposer, which could offer an interesting balance of performance and efficiency.
- Optimizing for Different Use Cases: As we continue to refine our approach, we'll be focusing on optimizing MOA configurations for specific use cases. This could involve creating specialized mixes for different programming languages, development frameworks, or types of coding tasks.
- Enhancing Evaluation Methodologies: While our current benchmarking approach using BigCodeBench provides valuable insights, we're looking to develop more comprehensive evaluation frameworks. These will help us better understand the nuanced performance characteristics of different MOA configurations across a wider range of coding scenarios.
The promising results we've achieved with our open-source MOA approach have reinforced our excitement about the future of MOAs in AI-assisted coding. By combining the strengths of multiple models, we can create systems that are not only more capable but also more efficient and cost-effective than traditional single-model approaches.
As we continue to push the boundaries of what's possible with MOAs, we invite the developer community to join us in this exploration. Whether you're interested in experimenting with different model combinations, optimizing for specific use cases, or developing new evaluation methodologies, there's a wealth of opportunity in this emerging field.
The future of AI-assisted coding lies not just in the development of more powerful individual models, but in our ability to intelligently combine and orchestrate multiple models to tackle complex coding challenges. With ongoing advancements in both open-source and commercial language models, coupled with innovative approaches like MOAs, we're entering an exciting new era of AI-augmented software development.