Leveraging AI Leaderboards for Model Selection
Selecting and integrating the most suitable AI language models for specific tasks can be challenging for developers and organizations. Index mixes offer a solution to this problem by automating the process of model selection based on performance metrics from established AI leaderboards. This article examines index mixes, their implementation on Crosshatch, and their potential impact on AI development and deployment.
TL;DR: Index mixes automate AI model selection by routing requests to high-performing models for specific tasks, based on leaderboards like the LMSys Chatbot Arena. This approach simplifies integration, potentially improves performance, and allows applications to benefit from AI advancements without constant updates.
The article covers the following topics:
- Definition and mechanics of index mixes
- Challenges in LLM evaluation and how index mixes address them
- Practical benefits of using index mixes for development and deployment
- Current index mixes available on Crosshatch
- Future developments and expansion plans for index mixes
This information is relevant for AI developers, businesses integrating language models, and those interested in efficient AI deployment strategies. The article aims to provide a clear understanding of index mixes and their role in streamlining AI integration.
What are Index Mixes?
Index mixes represent a novel approach to leveraging the rapidly evolving landscape of LLMs. At their core, index mixes are dynamic endpoints that automatically route user requests to the best-performing AI models based on established leaderboards. This innovative concept aims to solve one of the most persistent challenges in AI development: ensuring access to top-tier model performance without constant manual updates.
The fundamental goal of index mixes is to provide users with an endpoint that consistently connects them to the "known best" model according to a specified definition of quality. This approach acknowledges a crucial reality in the world of AI: the notion of "best" in LLMs is complex and often difficult to define unambiguously. However, by adopting a consistent method of determining quality—whether it's measured by user preference, task-specific correctness, or other metrics—index mixes offer a reliable way to access high-performing models.
Unlike synthesis mixes, which combine outputs from multiple models, index mixes don't return an answer that is an amalgamation of various model generations. Instead, Crosshatch employs sophisticated routing logic to direct each request to a single, high-performing model. While a simple failover strategy (trying the top-ranked model, then the second if the first fails, and so on) is one possibility, Crosshatch opts for a more nuanced approach.
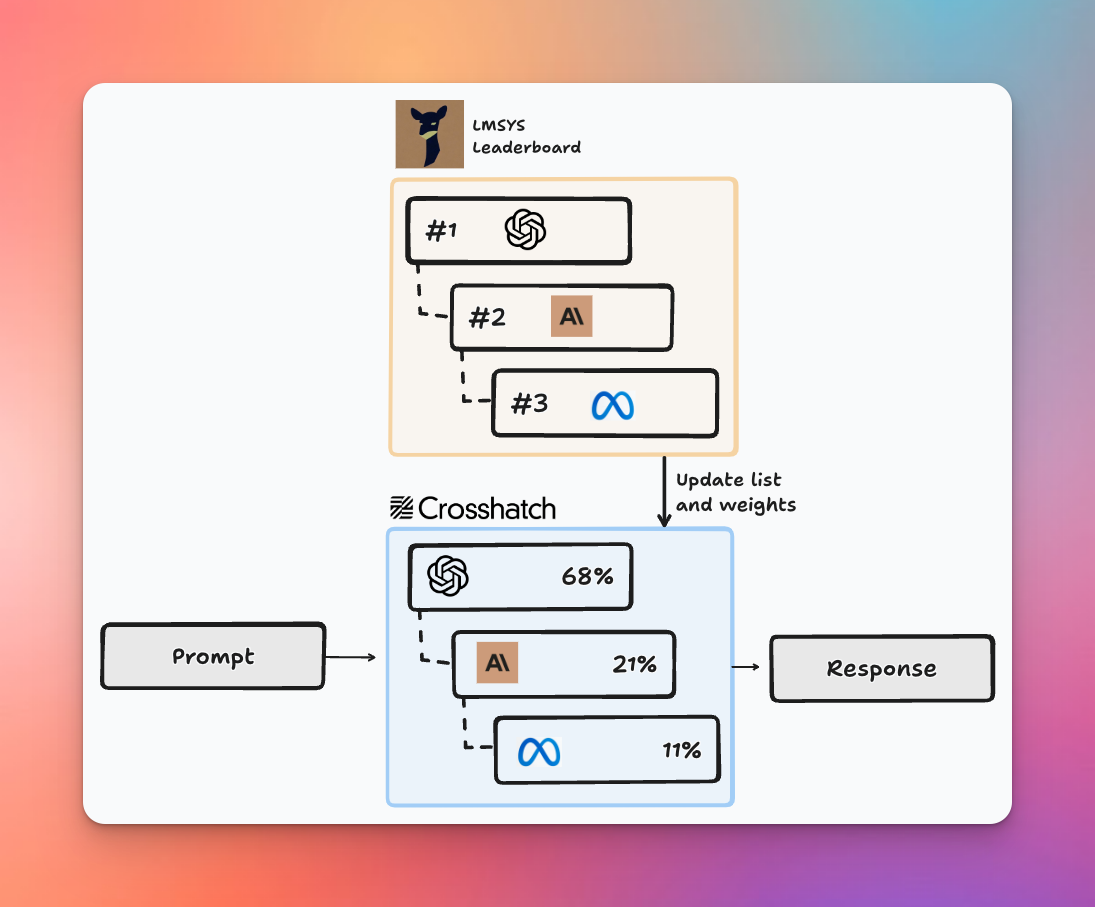
The routing logic in Crosshatch's index mixes weighs the probability of a model being selected based on its score and other relevant factors. For instance, when using a leaderboard like the Chatbot Arena, which provides user preference evaluations along with the number of votes and variance, the selection algorithm considers all these elements. This approach ensures that users are more likely to interact with models that consistently perform well, rather than those that might temporarily top the leaderboard but have high variance or limited data points.
One of the key benefits of index mixes is their inherent robustness. If one model fails or is unavailable, the system automatically routes the request to the next best option. This built-in failover mechanism ensures high availability and reliability, critical factors for many real-world applications.
A significant implication of using index mixes is that prompts no longer need to be tailored to specific models. While general best practices for prompt design still apply, users are freed from the need to consider model-specific idiosyncrasies. For example, the knowledge that Anthropic models prefer XML formatting while OpenAI models work better with markdown becomes less relevant. This shift allows developers and users to focus on crafting high-quality, generalized prompts that work well across a range of top-performing models.
In essence, index mixes represent a paradigm shift in how we interact with AI models. By abstracting away the complexities of model selection and providing a dynamic, performance-based routing system, they offer a more flexible, robust, and future-proof approach to leveraging the power of large language models.
The Mechanics of Index Mixes
At its core, the process of creating an index mix involves leveraging existing LLM leaderboards to determine which models to include and how to weight them. However, this seemingly straightforward approach is complicated by the inherent difficulties in objectively evaluating LLM quality.
The Challenge of LLM Evaluation
There's no such thing as a truly objective evaluation of LLM quality. The effectiveness of an LLM ultimately depends on how well it performs for a specific application and its associated quality criteria. While generalized evaluations offer valuable apples-to-apples comparisons, they face significant challenges:
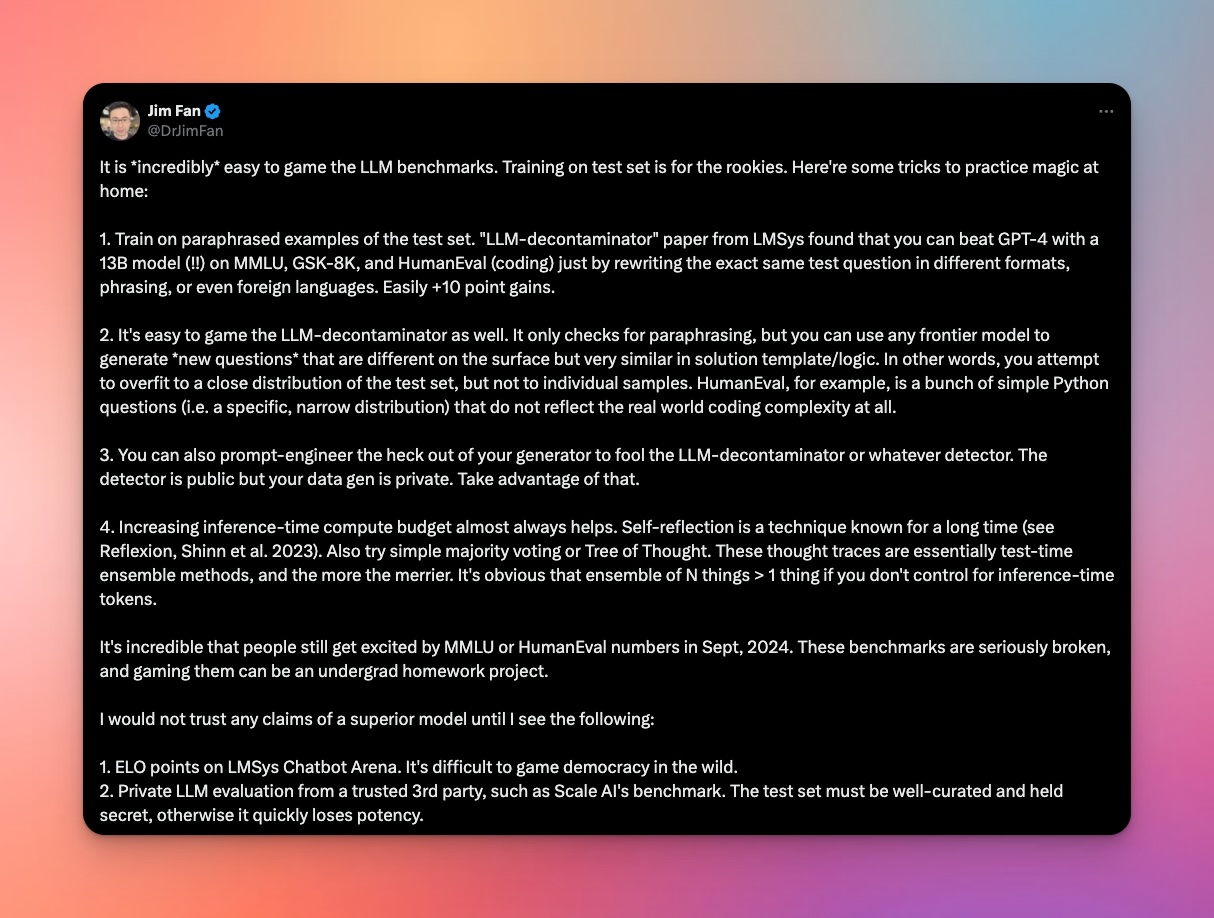
- Memorization and Overfitting: Many popular benchmarks are publicly available, which means they may have been included in the training data of newer models. This can lead to artificially inflated performance scores. As highlighted in recent research, some models have been found to repeat verbatim examples from test sets of benchmarks like MATH and GSM8k.
- Rapid Saturation: The pace of LLM development has dramatically reduced the time between a benchmark's creation and its saturation (when model performance exceeds human performance). This makes it difficult to rely on static benchmarks for long-term evaluation.
- Pressure to Perform: With billions of dollars at stake in the AI industry, there's immense pressure to perform well on public benchmarks. This can lead to overfitting through techniques like synthetic data creation, which may inadvertently reflect test data rather than real-world applications.
The LLM community has grappled with these evaluation challenges, leading to a shift towards more use-case specific evaluations with custom datasets. However, the reality is that many developers and researchers resort to "vibes-based development" – relying on intuition and direct interaction to assess a model's capabilities.
Crosshatch's Approach to Index Mixes
Recognizing these challenges, Crosshatch has developed a nuanced approach to creating index mixes that attempts to balance the need for objective metrics with the realities of LLM evaluation:
- Leveraging Democratic Evaluation: Crosshatch primarily uses the LMSys Chatbot Arena leaderboard as a key input for its index mixes. This platform crowd-sources user ratings through blind A/B test conversations, making it more difficult to game than traditional benchmarks. As noted by AI researcher Jim Fan, "It's difficult to game democracy in the wild."
- Incorporating Private Evaluations: To complement the public LMSys data, Crosshatch also utilizes the SEAL AI leaderboards, which use private datasets. This helps mitigate the risk of data leakage and training set contamination.
- Sophisticated Weight Calculation: When new LMSys numbers are released, Crosshatch fetches the raw data from Hugging Face to calculate weights and regenerate its mixes. The weight calculation for each model is based on three factors:Each factor is normalized to a 0-1 scale based on its min and max values across all models. For variance, a lower value is considered better, so it's inverted. After calculating these initial weights, they're further adjusted to ensure a minimum weight ratio, then normalized so all weights sum to 1. This approach aims to favor models with higher ratings, lower variance (more consistent performance), and more battles (more data points), while still giving some weight to all models in the mix.
- Rating (70% contribution)
- Variance (15% contribution)
- Number of battles (15% contribution)
- Dynamic Pricing: The price of a mix reflects the expected cost based on the most up-to-date price of each model, its weight in the mix, and a small margin to cover infrastructure costs.
Limitations and Considerations
While Crosshatch's approach to index mixes attempts to address many of the challenges in LLM evaluation, it's important to acknowledge its limitations:
- The LMSys Chatbot Arena, while robust, is not perfect. As Jim Fan notes, it can be noisy (with some users not examining outputs carefully), biased towards a tech-savvy population, and limited in evaluating certain capabilities like coding skills.
- The use of public leaderboards, even crowd-sourced ones, still carries some risk of gaming or optimization over time.
- The weighting system, while sophisticated, is still based on generalized performance metrics rather than task-specific evaluations.
The Future of Index Mixes
As the field of LLM evaluation continues to evolve, so too will the mechanics of index mixes. Future iterations may incorporate:
- More diverse evaluation sources, including task-specific benchmarks
- Advanced techniques to detect and mitigate overfitting or gaming of evaluation metrics
- Integration of real-time user feedback to continually refine model selection and weighting
By leveraging a combination of public and private evaluations, sophisticated weighting algorithms, and a dynamic approach to model selection, Crosshatch's index mixes aim to provide users with access to top-performing models while acknowledging the complexities and limitations of current LLM evaluation methods.
Why Index Mixes Matter
1. Always Using Top-Performing Models for Specific Use Cases
Index mixes ensure access to the best available AI models for specific tasks or domains. They are built around particular use cases, such as coding (based on the LMSys Coding Leaderboard) or language-specific tasks (like the SEAL AI Spanish leaderboard). This targeted approach allows developers to focus on application development, confident that they're utilizing the most suitable model for their specific needs. As new models emerge and performance rankings shift, index mixes automatically adapt, ensuring consistent access to top-tier capabilities without manual intervention.
2. Simplifying Model Selection for Developers
The complexity of choosing the right AI model is significantly reduced with index mixes. Developers no longer need to spend valuable time researching, testing, and comparing different models for each project or use case. Instead, they can rely on the index mix to route their requests to the most appropriate high-performing model based on up-to-date evaluations and sophisticated weighting algorithms. This simplification allows developers to concentrate on core application logic and user experience rather than the intricacies of model selection.
3. Future-Proofing Applications
Applications built using index mixes are inherently future-proofed against model obsolescence. As new, more capable models are developed and added to leaderboards, index mixes automatically incorporate them into their routing logic. This means that applications can benefit from advancements in AI without requiring significant code changes or re-architecture, extending the lifespan and relevance of AI-powered features.
4. Speed Optimization
Index mixes prioritize performance speed alongside model capability. Crosshatch, for instance, automatically selects the fastest available endpoint for open-source models like Llama 3.1 405B. Providers known for their speed, such as Groq, are chosen by default when available. This focus on speed optimization ensures that applications not only leverage top-performing models but also deliver results with minimal latency, enhancing user experience and system efficiency.
5. Increased Reliability and Robustness
The multi-model approach of index mixes inherently provides greater system reliability. If one model is temporarily unavailable or experiencing issues, requests can be seamlessly routed to alternative high-performing models. This built-in redundancy ensures higher uptime and more consistent performance for AI-powered applications, reducing the risk of service interruptions and maintaining a smooth user experience.
Available Index Mixes in Crosshatch
Crosshatch offers a diverse range of index mixes, each tailored to specific use cases and built on trusted leaderboards. These mixes are designed to cater to various needs across different industries and applications. Let's explore the current offerings and future directions for Crosshatch's index mixes.
Current Index Mixes
Crosshatch's current lineup of index mixes is primarily based on the LMSys leaderboards, known for their comprehensive and up-to-date evaluations of AI models. These mixes include:
- Coding Mix
- Use case: Optimized for code understanding and generation
- Target audience: Software developers, tech companies, and coding education platforms
- Ideal for: IDE integrations, code review tools, and programming tutorials
- Language-Specific Mixes
- Available for: Japanese, Korean, Chinese, French, Spanish, Russian, and German
- Use case: Enhanced performance in specific languages
- Target audience: Localization teams, international businesses, and language learning applications
- Ideal for: Translation services, localized chatbots, and language-specific content creation
- Multi-turn Conversation Mix
- Use case: Improved performance in chat-like contexts with many turns
- Target audience: Customer service platforms, interactive storytelling apps, and conversational AI developers
- Ideal for: Chatbots, virtual assistants, and interactive narrative experiences
- Vision Mix
- Use case: Best-performing models that support image processing and understanding
- Target audience: Computer vision researchers, e-commerce platforms, and media analysis tools
- Ideal for: Image recognition, visual search, and multimodal AI applications
Open Source Alternatives
In line with Crosshatch's commitment to open source AI, we are also preparing filtered versions of these mixes that exclusively use open source models. These alternatives will provide similar capabilities while offering greater transparency and customization options.
Who Should Use Index Mixes?
Index mixes are particularly beneficial for:
- Startups and SMEs: Access top-tier AI capabilities without the overhead of managing multiple model integrations
- Enterprise developers: Quickly implement and scale AI features across various applications and use cases
- Researchers: Use the best model for the task without worrying too much about the details
- Education platforms: Provide students and learners with access to state-of-the-art AI tools
- AI enthusiasts: Experiment with cutting-edge models without the complexity of individual setups
The Future of Index Mixes
Crosshatch is committed to expanding and enhancing its index mix offerings. Our future plans include:
- Expanded Catalogue: We aim to introduce new index mixes by:
- Incorporating additional leaderboard providers
- Exploring new use cases and domains
- Developing innovative scoring mechanisms to better capture model performance
- Faster Updates: We're working towards partnerships with leaderboard developers to enable more rapid updates to our mixes, ensuring even more up-to-date performance.
- User Feedback Integration: Leveraging DecentAI, our mobile app where users can interact with a wide variety of LLMs, we plan to incorporate user feedback to:
- Create new mixes based on real-world performance and preferences
- Fine-tune scoring mechanisms to better reflect practical usage scenarios
- Commitment to Open Source: We remain dedicated to open source AI and transparency. This commitment will guide our development of new mixes and the continuous improvement of existing ones.
- Customization Options: In the future, we aim to offer more customization options, allowing users to tweak mix parameters to better suit their specific needs.
By continually expanding and refining our index mix offerings, Crosshatch aims to stay at the forefront of AI integration, making advanced language models more accessible and effective for a wide range of users and applications.